Position Management¶
Design¶
Note
The position manager is a drop-copy client to the gateway: it will receive all trade updates for all users.
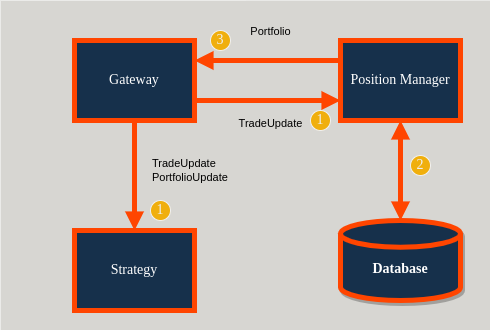
Constraints¶
The design requires
Exactly one position manager per gateway (
source).
Functional¶
Responsibilities include
Receive
roq::TradeUpdatemessages (drop-copy, i.e. listening to all events).Upload trade history to a database.
Aggregate trade history into net long/short positions.
Publish positions back to the gateway as
roq::Portfolio.
Portfolios¶
Positions are aggregated into portfolios with the following keys (at least one must be “non-empty”)
userstrategy_idaccount
For each such aggregation level, there can be multiple positions, each keyed by
exchangesymbol
Synchronization¶
The position manager will ensure the following information is associated with trades uploaded to the database
source_session_id(gateway session id, UUID)source_seqno(gateway sequence number, unique only for the session)
The last known gateway session and sequence number will be associated with any new positions computed by the position manager.
Portfolios sent to the gateway can then include the most recent gateway session and sequence number from which it is was computed.
Finally, the gateway can correlate the sequence number with its trade history, discard any trades prior to the received sequence number, and overlay any trades after the sequence number.
This is how it works
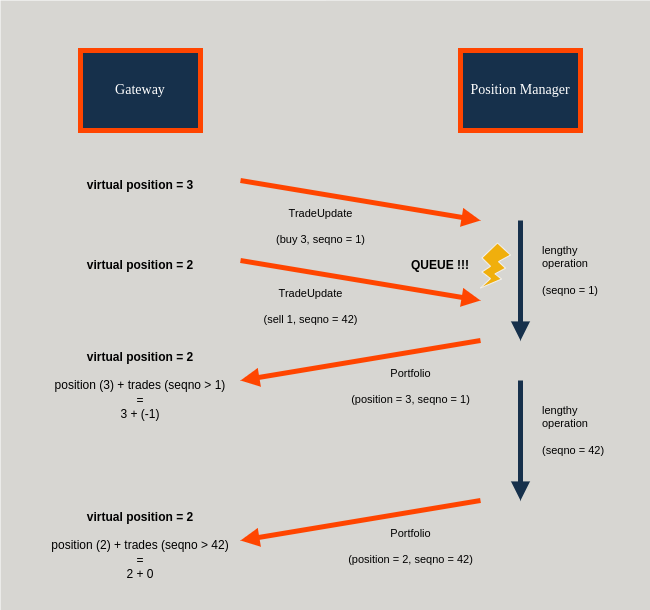
Note
There is no latency when computing virtual positions.
The use of sequence numbers is there to guarantee synchronization.
We note that the roq::Portfolio messages arrive late (after two lengthy operation) and that
the virtual position remains unchanged (meaning: the zero-latency implementation was correct).
Database¶
The following tables are used
The
tradestable is a buffer used to save all trades received by the position manager.The
trades_2table is used to save unique trades.The
portfoliotable is used to save aggregated positions.

Note
Primary key is indicated by (*).
De-duplication column is indicated by (+).
The column named batch_id is special and its usage is described in this documents.
Some complications arise partly because of duplicated trade updates and partly because of performance constraints.
De-Duplication¶
Trades can be duplicated for these reasons
Download. Each time the gateway reconnects to the exchange, it will download trades for some lookback period. This is done to catch any fills that could have happened while the gateway was disconnected. The gateway will filter any trades that it has already seen after process start (no fields were updated). But there may be duplicates (vs database) first time it downloads after process start.
Multiple updates. Some venues may update certain trade attributes at different times. This often happens as part of credit checks, clearing, or other admin related tasks. The result is that the same trade may be reported again. The gateway will not filter these updates (one or more fields were indeed updated).
The result of this is that the position manager must correctly manage de-duplication before aggregating positions.
The trades_2 table is used for this purpose.
It will contain the last seen version of a trade at the time it was inserted.
Any further updates to the trade (inserted into the trades table) will not be copied to the trades_2 table.
In summary
The
tradestable is a buffer table that may include duplicates.The
trades_2table contains a single version of a trade (possibly an older version from thetradestable).
Performance¶
The other complication is around performance: It is extremely inefficient to insert each trade by itself, then de-duplicate and then aggregate positions.
The position manager must therefore buffer trade updates and only insert batches into the trades table.
When a batch has been inserted, the position manager will try to copy new trades to the trades_2 table.
This will be done by appending a batch_id field to each row being copied.
After de-duplication, any new trades can be found in the trades_2 table having this batch_id.
Note
There are no new trades if no rows can be retrieved for that batch_id.
The following steps can then be discarded and the batch_id can be recycled for next iteration of the
procedure described here.
The distinct combination of exchange and symbol for that batch_id can now be used to aggregate positions.
These new positions are inserted into the portfolio table along with the batch_id and also the last
seen source_session_id and source_seqno from the trades_2 table.
Finally, the updated positions can be fetched from the portfolio table for that batch_id and
published to the gateway using the roq::Portfolio message.
Gateway¶
Portfolios¶
The gateway will cache portfolios by each of user, strategy_id and account.
Note
The implication is therefore that a trade can belong to more portfolios. Users (strategies) can decide what aggregation level is more important for the use case.
Trades happening after initial download will be cached with each matching portfolio.
The gateway is allowed to overlay this trade to existing positions if a
roq::Portfoliohas been received from the position manager. It can then publish this approximation asroq::PortfolioUpdateto connected users.When the gateway receives a
roq::Portfoliofrom the position manager, it will discard (and remove) any trades prior tosource_seqnoiff thesource_session_idmatches that of the current gateway session. The finalroq::PortfolioUpdatemessage will be the sum ofroq::Portfolioand any trades currently cached.
Latency¶
Clients will see roq::TradeUpdate immediately followed by roq::PortfolioUpdate.
The described design hides all latencies involved with computing aggregated positions.
Other Use-Cases¶
The trades_2 can be used as a “source of truth”. It will contain each trade exactly once.
However
The table is updated “late” because it’s the result of buffering and queuing. The only suggested solution is to implement a custom drop-copy solution which will cache all the trade history in memory and effectively manage the de-duplication and aggregation in-process.
Trades will appear in batches. Sometimes this is good, e.g. when many fills appear simultaneously for a resting limit order. However, it may also be an issue for use-cases requiring a live and ordered trade feed, e.g. risk calculations. The only suggested solution is to order by
exchange_time_utc(when available) and consume the fills in batches for a matching timestamp.